
티스토리 뷰
openCV Python을 사용하려면 NumPy의 기초적인 기능을 이해해야 한다. NumPy는 행렬이나 일반적으로 다차원 배열을 쉽게 처리할 수 있도록 지원하는 파이썬의 라이브러리이다.
Numpy 라이브러리는 왜 사용하는가?
이미지는 여러 개의 픽셀들의 값으로 구성되므로 수많은 행과 열로 구성된 픽셀 데이터들의 모음이다. 이 픽셀 데이터들을 프로그래밍 영역에서 다루려면 픽셀 값들을 저장하고 관리 할 적절한 자료구조가 필요한데 이것이 NumPy 이다.
NumPy 기본 속성
- ndim: 차원(축)의 수
- shape: 각 차원의 크기(튜플)
- size: 전체 요소의 개수, shape의 각 항목의 곱
- dtype: 요소의 데이터 타입
- itemsize: 각 요소의 바이트 크기
OpenCV 의 이미지 구조
- 이미지를 3차원 배열 (행 X 열 X 채널) 로 표현한다.
- 행(= 높이)과 열(=폭)은 이미지의 크기를, 채널은 컬러인 경우 파랑, 초롱, 빨강 3개의 길이를 갖는다.
- 즉 이미지를 읽었을 때 (높이 X 폭 X 3) 의 형태가 된다.
NumPy 배열 메소드
- 값으로 생성: array()
- 초기 값으로 생성: empty(), zeros(), ones(), full()
- 기존 배열로 생성: empty_like(), zeros_like(), ones_like(), full_like()
- 순차적인(시퀸스) 값으로 생성: arange()
- 난수로 생성: random.rand(), random.randn()
1. 값으로 생성
numpy.array(list, [dtype])
- list: 배열 생성에 사용할 값을 갖는 파이썬 리스트 객체
- dtype: 데이터 타입
- int8, int16, int32, int64: 부호 있는 정수
- uint8, uint16, uint32, uint64: 부호 없는 정수
- float16, float32, float64, float128: 부동 소수점을 갖는 실수
- complex64, complex128, complex256: 부동 소수점을 갖는 복소수
- bool: (boolean)
2. 크기와 초기 값으로 생성
- numpy.empty(shape,[dtype]): 초기화 되지 않은 값(쓰레기 값) 으로 배열 생성
- shape: 튜플, 배열의 각 차수의 크기 지정
- numpy.zeros(shape,[dtype]): 0으로 초기화된 배열 생성
- numpy.ones(shape,[dtype]): 1로 초기화된 배열 생성
- numpy.full(shape,fill_value,[dtype]): fill_value로 초기화된 배열 생성
3. 기존 배열 복사
- empty_like(array, [dtype]): 초기화되지 않은, array와 같은 shape와 dtype의 배열 생성
- zeros_like(array, [dtype]): 0으로 초기화된, array와 같은 shape와 dtype의 배열 생성
- ones_like(array, [dtype]): 1로 초기화된, array와 같은 shape와 dtype의 배열 생성
- full_like(array, fill_value, [dtype]): fill_value로 초기화된, array와 같은 shape와 dtype 배열 생성
4. 시퀸스와 난수로 생성
numpy.arrange([start=0],stop, [step=1, dtype=float64]): 순차적인 값으로 생성
- start: 시작 값
- stop: 종료 값, 범위에 포함하는 수는 stop -1 까지
- step: 증가 값
- dtype: 데이터 타입
numpy.random.rand([d0, [d1 [...., dn]]): 0과 1 사이의 무작위 수로 생성
- d0, d1....dn: shape, 생략하면 난수 한개 반환
numpy.random.randn([d0, [d1 [..., dn]]]): 표준 정규 뷴포(평균: 0, 분산: 1)를 따르는 무작위 수로 생성
5. dtype 변경
- ndarray.astype(dtype)
- dtype: 변경하고 싶은 dtype, 문자열 또는 dtype
- numpy.uintXX(array): array를 부호 없는 정수(uint) 타입으로 변경해서 반환
- uintXX: uint8, uint16, uint32, uint64
- numpy.intXX(array): array를 부호 있는 정수(int) 타입으로 변경해서 반환
- intXX: int8, int16, int32, int64
- numpy.floatXX(array): array를 float 타입으로 변경해서 반환
- floatXX: float16, float32, float64, float128
- numpy.complexXX(array): array를 복소수 타입으로 변경해서 반환
- complexXX: complex64, complex128, complex256
6. 차원 변경
- ndarray.reshape(newshape): ndarray의 shape를 newshape로 차원 변경
- numpy.reshape(ndarray,newshape): ndarray의 shape를 newshape로 차원 변경
- ndarray: 원본 배열 객체
- newshape: 변경하고자 하는 새로운 shape(튜플)
- numpy.ravel(ndarray): 1차원 배열로 차원 변경
- ndarray: 변경할 원본 배열
- ndarray.T: 전치배열(transpose)
reshape의 파라미터에 '-1' 를 넣으면 해당 차수에 대해서는 알아서 크기를 지정하라는 뜻이 되어 불필요한 계산을 할 필요가 없어지는 유용한 기능이다. 하지만 101개의 요소를 2개의 열로 알아서 크기를 나누라는 식의 연산은 오류를 반환하니 조심하자.
7. 브로드캐스팅 연산
NumPy에서 지원하는 브로드캐스팅은 병렬연산이라고 볼 수 있겠다. 만약 NumPy를 사용하지 않고 브로드캐스팅 연산을 한다면 아래와 같다.
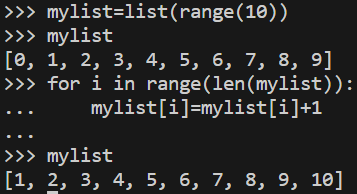
그럼 numPy를 이용해서 브로드캐스팅 연산을 해보면 아래와 같다.

이미지에서 보았듯이 배열 안의 모든 요소들이 동일한 연산을 수행하는 것을 볼 수 있다.
numPy의 브로드캐스팅 연산은 연산자를 지원한다.
지원하는 연산자
- +
- -
- *
- /
- ** (제곱)
- >, < (비교 연산자)
주의
numPy 브로드캐스팅 연산을 하기 위해선 몇가지 연산 규칙이 있다.
- 연산하고자 하는 두 배열의 shape가 일치해야 한다.
- 행열 연산과 비슷하지만 행렬 곱셈의 규칙과 다르니 조심하자
- 행 단위 연산을 하려면 두 배열의 행이 같아야 한다.
- 열 단위 연산을 하려면 두 배열의 열이 같아야 한다.
8. 인덱싱, 슬라이싱
numPy 배열도 특정 인덱스 요소에 접근할 수 있다. 접근 방법은 기존의 파이썬 리스트 인덱싱 방법과 같다.
기본 인덱싱,슬라이싱
- array [a,b]: 배열의 a행 b열의 요소를 인덱싱
- array[2:5]: 배열의 인덱스~부터 인덱스4 까지의 요소들을 슬라이싱
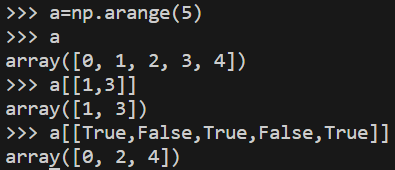
팬시 인덱싱
배열 인덱스에 다른 배열을 전달해서 원하는 요소를 선택하는 방법, 전달하는 배열에 숫자를 포함하고 있으면 해당 인덱스에 맞게 선택되고 배열에 bool값을 포함하면 True인 값을 갖는 요소만 선택된다.
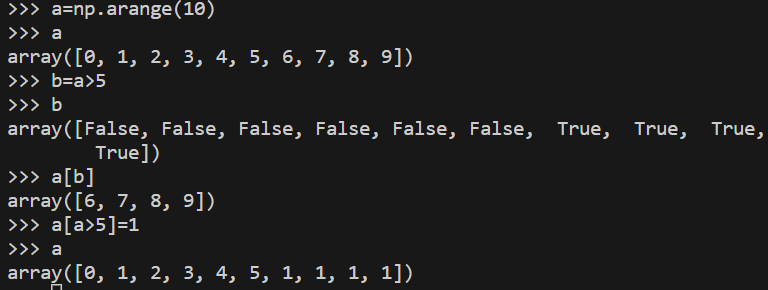
배열 요소가 특정 조건에 만족되면 추출하여 개별 연산시키는 것도 가능하다.
9. 배열 병합, 분리
2개 이상의 numPy 배열을 병합하는 방법은 크게 두 가지가 있다.
- 단순히 배열들을 이어 붙여서 크기를 키우는 방법
- 새로운 차원을 만들어 서로서로 끼워넣는 방법
배열 병합 메소드
- numpy.hstack(arrays): arrays 배열을 수평으로 병합
- numpy.vstack(arrays): arrays 배열을 수직으로 병합
- numpy.concatenate(arrays,axis=0): arrays 배열을 지정한 축 기준으로 병합
- numpy.stack(arrays, axis=0): arrays 배열을 새로운 축으로 병합
- arrays: 병합 대상 배열(튜플)
- axis: 작업할 대상 축 번호
배열 분리 메소드
- numpy.hsplit(array,indice): array 배열을 수평으로 분리
- numpy.vsplit(array,indice): array 배열을 수직으로 분리
- numpy.split(array, indice, axis=0): array 배열을 axis 축으로 분리
- array: 분리할 배열
- indice: 분리할 개수 또는 인덱스
- axis: 기준 축 번호
10. 검색
ret = numpy.where(condirion, [t,f]): 조건에 맞는 요소를 찾기
- ret: 검색 조건에 맞는 요소의 인덱스 또는 변경된 값으로 채워진 배열(튜플)
- condition: 검색에 사용할 조건식
- t,f: 조건에 따라 지정할 값 또는 배열, 배열의 경우 조건에 사용한 배열과 같은 shape
- t: 조건에 맞는 값에 지정할 값이나 배열
- f: 조건에 틀린 값에 지정할 값이나 배열
- numpy.nonzero(array): array에서 요소 중에 0이 아닌 요소의 인덱스들을 반환(튜플)
- numpy.all(array, [axis]): array의 모든 요소가 True인지 검색
- array: 검색 대상 배열
- axis: 검색할 기준 축, 생략하면 모든 요소 검색, 지정하면 축 개수별로 결과 반환
- numpy.any(array, [axis]): array의 어느 요소이든 True가 있는지 검색
11. 기초 통계 함수
- numpy.sum(array, [axis]): 배열의 합계 계산
- numpy.mean(array, [axis]): 배열의 평균 계산
- numpy.amin(array, [axis]): 배열의 최소 값 계산
- numpy.min(array, [axis]): amin() 과 동일
- numpy.amax(array, [axis]): 배열의 최대 값 계산
- numpy.max(array, [axis]): amax() 과 동일
- array: 계산의 대상 배열
- axis: 계산 기준 축, 생략하면 모든 요소를 대상
NumPy 활용한 예제
NumPy 를 활용하여 이미지를 생성해보기
흑백버전
import cv2
import numpy as np
img=np.zeros((120,120),dtype=np.uint8) # 120 X 120 2차원 배열 생성, 검은색 흑백 이미지
img[25:35,:]=45 # 25~35 행 모든 열에 45 할당
img[55:65,:]=115 # 55~65 행 모든 열에 115 할당
img[85:95,:]=160 # 85~95 행 모든 열에 160 할당
img[:,35:45]=205 # 모든 행, 35~45 열에 205 할당
img[:,75:85]=255 # 모든 행, 75~85 열에 255 할당
cv2.imshow('gray',img)
if cv2.waitKey(0)&0xff==27:
cv2.destroyAllWindows()

컬러 버전
import cv2
import numpy as np
img=np.zeros((120,120,3),dtype=np.uint8) # 120 X 120 2차원 배열 생성, RGB 이미지
img[25:35,:]=[255,0,0] # 25~35 행 모든 열에 파란색 할당
img[55:65,:]=[0,255,0] # 55~65 행 모든 열에 초록색 할당
img[85:95,:]=[0,0,255] # 85~95 행 모든 열에 빨간색 할당
img[:,35:45]=[255,255,0] # 모든 행, 35~45 열에 하늘색 할당
img[:,75:85]=[255,0,255] # 모든 행, 75~85 열에 분홍색 할당
cv2.imshow('gray',img)
if cv2.waitKey(0)&0xff==27:
cv2.destroyAllWindows()

'Opencv 공부' 카테고리의 다른 글
| [openCV] 관심 영역 지정하기 (1) | 2023.05.09 |
|---|---|
| [openCV] Matplotlib (1) | 2023.05.07 |
| [openCV] 각종 이벤트 함수 모음 (1) | 2023.05.04 |
| [openCV] 창 관리하기 (0) | 2023.05.01 |
| [openCV] 그림 그리기 (2) | 2023.04.30 |